
(一) 数据的分组
数据分组就是根据统计研究的需要,将数据按照某种标准划分成不同的组别。分组后再计算出各组中出现的次数和频数,形成一张频数分布表。分组的方法单变量值分组和组距分组两种。单变量值分组是把每一个变量值作为一组,这种分组方法通常只适用于离散变量且变量值较少的情况。在连续变量或变量值较多的情况下,通常采用组距分组。
组距分组是将全部变量值依次划分为若干区间,并将这一区间的变量值作为一组。下面结果具体的例子说明分组的过程和频数分布表的编制过程。
某高中一年级一共有55名学生,高一语文考试中成绩分别为:
59 73 87 65 89 85 77 94 69 97
56 80 68 95 96 50 63 88 91 90
96 92 93 79 74 65 74 89 83 51
74 79 94 67 92 92 93 70 87 86
54 87 86 54 62 76 86 73 86 70
100 110 108 102 112
第一步:确定分组组数。确定分组组数的要求是:第一,划分的组数,既不应太多也不应太少。组数过多,达不到通过分组压缩资料的目的;组数太少,将造成原始资料的信息丢失过多;第二,组数的确定,要尽量保证组间资料的差异性与组内资料的同质性;第三,采用的分组办法,要能够充分显示客观现象本身存在的状态。
统计分组:斯特基方法,其计算公式为 ,K为分组组数,N为数据个数。本例中, ,即应分7组
第二步,对原始资料进行排序。(略) jjsexam.CoM
第三步,求极差,即将最大的观察值与最小的观察值相减便得到极差。本例中为112-50=62
第四步,确定各组组距。组距=极差(全距)/组数
本例中,组距=62/7≈8.9,组距可取10。
组距与组数成反比关系,组数越多,组距越小,组数越少,组距越大。
组距=某组的上限值-该组的下限值
第五步,确定组限。
确定组限应注意:
第一,第一组的下限值应比最小的观察值小一点,最后一组的上限值应比最大的观察值大一点;
第二,特别需要或不得已的情况除外,最好不要使用开口组;
第三,组限应取得美观些,按数字编好,组限值应能被5除尽,且一般要用整数表示。
本例中,把第一组的下限值定为50,
第六步,确定各组观察值出现的频数。采用组距分组时,需要遵循“不重不漏”的原则。
为解决“不重”的问题,统计分组时习惯上规定“上组限不在内”,即当相邻两组的上下限重叠时,恰好等于某一组上限的观察值不算在本组内,而计算在下一组内。
第七步,制作频数分布表,并填上相关的内容,以及其他需要说明的事。
考试交流区报名时间交流群(点击加入QQ群可快速加群交流成绩查询相关信息我们会及时在群里通知):
 (群:569977370)
(群:569977370)
温馨提示:有任何报考及考试相关疑问,可添加网校专业老师个人微信号“edu24olxu”咨询。!考生可下载手机APP,随时掌握考试资讯!

扫一扫上面的二维码,添加老师个人微信号,所有课程八折开通
相关文章
如果本站所转载内容不慎侵犯了您的权益,请与我们联系
 ,我们将会及时处理。如转载本站内容,请注明来源:经济师考试网(jjsexam.COM)。
,我们将会及时处理。如转载本站内容,请注明来源:经济师考试网(jjsexam.COM)。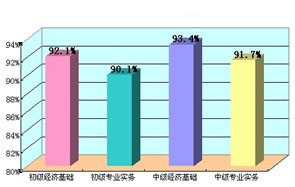
环球网校经济师历年通过率比较
 刘艳霞老师 |
刘艳霞老师:会计师、注册会计师。环球职业教育在线会计职称、注册税务师、注册会计师、会计从业、经济师等课程辅导专家。...[详细] |
 胡艳君老师 |
胡艳君老师,上海财经大学经济学博士。任职于北京某高校经济学类、管理学类的辅导老师。.[详细] |